
I spent ninety minutes last week trying to explain how galaxies expand.
I picked the topic on purpose. It's something I loved when I was younger, I've always been fascinated by space. I studied math and physics at a high level for a few years post-high school before I went into business school, and eventually into structured finance, but space is the thing I went to first the moment I tried Open Lesson.
Did I reconstruct the theory? Not at all, for obvious reasons (otherwise, I would be working for SpaceX and only a few months away from becoming a multimillionaire). But ninety minutes just disappeared and I did not see the time fly. I stopped past 1am, not exhausted, but with a focused and happy mind.
There is something about deep thinking that is properly entertaining.
What Open Lesson actually is
What I was using is called Open Lesson.
It is, on the surface, a chat with a blank page in the middle. You pick a topic, anything, and it starts asking you questions. It never gives you the answer. If you say "I don't know," it asks you what you'd need to know to figure it out. If you wander a bit, it lets you wander, and then it steers. If you try to bluff your way through, it notices. It is not here to be nice to you: not really what we've been used to when working with AI these past few years!
You can draw on the page, you can build a diagram of your reasoning. If you have a brainwave reader, you can plug it in, and the system watches your cognitive load while you think.
It is not an easy product to use. That is the point: it is a feature of the product, not a bug. And that is also why I like it.
The entire platform is based on a method you may have heard of: the Socratic method. Asking yourself why over and over again, until you solve your question. In fancier terms, quoting Wikipedia here:
The Socratic method is a form of argumentative dialogue in which an individual probes a conversation partner on a topic, using questions and clarifications, until the partner is pressed to come to a conclusion on their own, or else their reasoning breaks down and they are forced to admit ignorance.
What the science says
There is real research behind the idea that the friction is the point. I went looking for it before writing this, because I did not want to publish another post that just says "this thing feels great, try it." You can read that somewhere else. I read some of the papers from page 1 to end, while I restricted my read to the abstract for some others, depending on how meaningful they appeared to be. One core assumption on what they all seemed to agree: the aim of all instruction is to alter long-term memory, and if there is no change, there is no learning.
Michelene Chi and Ruth Wylie's ICAP framework (2014) ranks four levels of engagement: Interactive, Constructive, Active, Passive. Dialogue with feedback beats generating answers alone, which beats note-taking, which beats sitting in a lecture. The hierarchy is well-replicated. This explains also why a classroom full of students is not the most efficient learning environment: at best, it is a compromise.
A 225-study meta-analysis published in PNAS (Freeman et al., 2014) showed that students in active-learning STEM (Science, Technology, Engineering, Mathematics) classes scored about 6% higher on exams than students in traditional lectures, and were 1.5 times less likely to fail. The largest effect was on concept inventories, meaning actual conceptual understanding rather than memorized procedure.
Kurt VanLehn's 2011 synthesis of tutoring research is the cleanest evidence on what matters. Human one-on-one tutoring was statistically on par with step-based intelligent tutoring systems (d ≈ 0.79). The active ingredient turned out not to be the "humanness" of the tutor, but the granularity of the dialogue — whether the system intervenes at the answer level or step-by-step inside your reasoning.
This is exactly what Daniel, the founder of Open Lesson, is trying to model. Most of his fine-tuning is going towards when the AI tutor is stepping in to assist the learner. Understanding the context, the struggle, the difficulty of the question, so that it knows when to actually get active. Playing with the limit between frustration and engagement.
There is a more specific finding that underwrites the whole Socratic approach. It is called productive failure, and it comes from Manu Kapur.
In Kapur's foundational 2008 study, two groups of 11th-grade physics students worked on Newtonian kinematics problems (i.e. physics problems that describe motion: how fast something goes, how far, in what direction, etc.). The first group got direct instruction and well-structured problems. The second group got messy, ill-structured problems with no instruction, and most of them produced poor solutions. They failed. On the post-test though, this second group significantly outperformed the first, on both standard problems and on harder transfer problems (defined as a problem where you transfer knowledge and skills to a new context rather than just repeating a procedure you just learned). This finding was later confirmed and generalized by further research by Kapur, this time with Sinha, in a 2021 meta-analysis covering 166 experimental comparisons across roughly 12,000 participants. In a more recent paper, Kapur, together with Roll, established important principles for successful implementation of a productive-failure approach.
There is however one important condition. A 2021 replication and extension from Sinha, Kapur and ETH Zürich colleagues sharpened the design principle: scaffolding that increases failure-likelihood by challenging the learner's current understanding outperformed scaffolding that reduced task complexity to help the learner succeed. The struggle has to be real, not staged.
Two further lines of work explain the underlying cognitive mechanism. Chi's 1994 study on self-explanation found that 8th-graders prompted to explain a biology passage to themselves outperformed unprompted readers by roughly a third on transfer questions. A 2018 meta-analysis by Bisra and colleagues pooled 64 studies and put the average effect of prompted self-explanation at g = 0.55, the same effectiveness tier as mastery learning and one-on-one tutoring.
Robert and Elizabeth Bjork's "desirable difficulties" framework (2011) provides the theory underneath. (We curate a full shelf on memory and learning and another on learning theories if this research pulls you in.) Conditions of instruction that make performance improve rapidly often fail to support long-term retention and transfer. Conditions that create difficulties for the learner often optimize long-term retention and transfer. I'd recommend that paper to any parent investigating the best methods to support his/her child with learning: it covers different ways to learn well, for example spaced repetition, interleaving, etc. Open Lesson withholding the answer is exactly favoring your long-term retention and clear understanding of the underlying concepts, rather than just giving you an answer you can repeat like a parrot over the following week, but without the capability to explain why to anyone who'd ask you for more details.
On the frontier of all this, Google DeepMind's LearnLM team published an exploratory randomized controlled trial in late 2025 showing that supervised AI tutoring matched human tutors on every learning outcome and improved transfer to novel problems by 5.5 percentage points. Now, the confidence interval crosses zero (meaning, there are chances this is just statistical noise, not a real effect), the sample is small (165 participants in a handful of UK classrooms, with a focus on mathematics), the duration is short. The direction is however right yet the evidence base remains thin. Let's not forget this is only an exploratory RCT, therefore laying out the way for more studies, and nothing else for now. The human teachers who took part to that trial all concluded on the positive impact of AI, even on their own personal way of tutoring. The paper however highlighted the importance of not frustrating the students, which was not an easy task with AI tutoring system available: human tutors are much more sensitive in that respect. They draw on experience, empathy, and judgment gained over years of teaching.
Ok, so why don't we only use the Socratic method in our schools? Could it be the method that could solve all the problems of our modern education systems. Well, this is not that easy. As you may guess, this method is not new: it comes from Socrates... and it requires a tutor that knows well the topic you are trying to learn, conditions that are close to one-to-one tutoring. This is not scalable in schools.
Besides, in all honesty, the evidence is not one-sided. The most-cited critique of this method is Kirschner, Sweller and Clark (2006), "Why Minimal Guidance During Instruction Does Not Work." Their argument, from cognitive load theory, is that working memory is brutally limited — roughly four items and thirty seconds for unfamiliar material. Asking a true novice to "discover" the answer burns out their working memory on search, and nothing makes it into long-term memory. Kalyuga and colleagues then established what is called the expertise reversal effect: instructional techniques that work well for novices can actively hurt experts, and vice versa. The paper argues that the benefits of minimal guidance or problem-based learning only show for more advanced students: it is not helpful for novices, to the contrary.
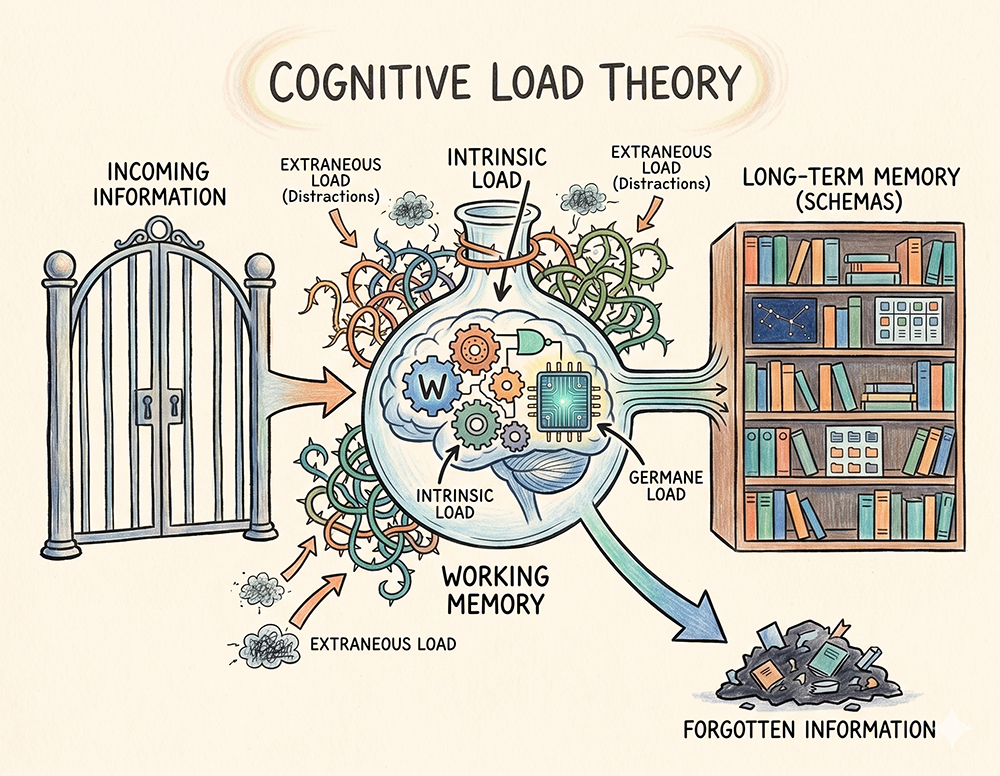 The Working Memory Bottleneck. Source: AI generated.
The Working Memory Bottleneck. Source: AI generated.
For me, this is key. This method assumes some prior knowledge. Without basics, you cannot get started. It can work for philosophy, where you're asked to think about a topic, without any required prerequisites. For science, I find it much more difficult. I noticed it myself when I tried to explain how galaxies expand. At some point, I lacked the foundational knowledge to go further, and I started going in a circle. And I eventually gave up.
Another downside of that method is that it is less replicable for non-STEMs subjects. You cannot expect learning a language with that method, even though it may help with some minor aspects. Likewise, it has limited applicability for students in history. These are just a couple of examples, but you can see where I'm getting at: any topic that emphasizes ambiguity, interpretation, or argumentation may not necessarily be the best suited for that method. And even less under the constraints of being AI generated.
The pedagogy is not a winner-takes-all argument. It is expertise-dependent. Hence again, Socratic dialogue is not a universal method, it is the right tool once a learner has enough schema in long-term memory to actually generate hypotheses worth interrogating. For a true novice staring at a blank page, "What do you think?" is cognitive cruelty, not guidance: working memory burns out on search and nothing lands in long-term memory. It may even disgust the learner and turn him off for good. The empirical sweet spot is worked example first, Socratic second — explicit instruction to install the schema, then questioning to stress-test and transfer it. A Socratic AI that never gives the answer is malpractice for the blank slate, and a superpower for the already-competent.
Therefore, Open Lesson works for a Dantes reader who would have put in the effort to go through the beginner material first, because they'd then arrive as intermediates, not as blank slates: Dantes hands them the bookshelf, and only then does Open Lesson put them in front of the desk.
Yet the best form of learning is a mix of different methods. Some learners are more receptive to one methodology than to another, but to get the fuller effects, it is best to expose oneself to a few complementary methods.
Why I didn't build this inside Dantes
You'll have spotted the obvious question. If I think this works, why didn't I build it inside Dantes?
I could have: "Claude, code a tool using the Socratic method integrated to Dantes. Please make no mistake" — and come back an hour later to a (likely partially) working product. The reason I didn't comes down to two things.
The first is the business model. Using an AI tutor means paying for tokens... which in turns means charging users. As such, Dantes would stop being free, and that breaks the entire project for me. This is not the philosophy behind Dantes, the one I read in The Count of Monte Cristo.
The second reason follows from the first. Building a thin wrapper around an LLM to call it "the Dantes tutor" would have been low-value AI for the sake of having AI. It would have produced what many other products in this category are producing right now, which is a chatbot that pretends to teach by giving you the answer slightly faster than Google would. That is not what I wanted to ship at all. Daniel has a strong background in software engineering and he has been working for a long time on the science of learning. I would not have been able to build something as sophisticated as he did.
And underneath both of those reasons, there is a deeper one. The internet was meant to be a free community. I grew up at a time where you had forums on every possible niche you could think of, and people would socialize there, share their best tips and recommendations, help each other. This was a free world, full of builders. I grew up with it and absolutely loved it. I feel that nowadays, too many people are trying to monetize everything. I am a liberal so I won't forbid them to do so. I just find that a bit sad: not everything should be about money. And if you know me IRL, you can quote me on that. (But I am not against making money, I work in finance after all...)
What Daniel built that a wrapper isn't
Open Lesson is built by Daniel Colomer, who goes by UncertainSystems online. He is a software engineer who has been working on the science of learning for a long time. Open Lesson is one product inside a broader ecosystem he is building at uncertain.systems. The ecosystem's motto is:
"Building the open stack for educational technology."
Open Lesson is one layer in that stack, not a standalone product.
The stack is not metaphorical. It has four pieces, and three of them already exist publicly. Open Lesson is the front-end, the Socratic think-aloud harness I have been describing. Underneath sits the GHC dataset, which Daniel calls Genuine Human Cognition. It contains real-time multimodal traces of people explaining their reasoning out loud, with transcripts, facial-expression analysis, and tool-use detection, all hosted on Hugging Face under Apache-2.0. Alongside the dataset, there is the GHC benchmark, which scores how closely a model's reasoning matches actual human reasoning. Daniel built it for Google DeepMind and Kaggle's "Measuring Progress Toward AGI" competition, on the metacognition track. The fourth piece, called Classroom, is still in development: a simulator for training synthetic tutors and synthetic students at scale. That is what will eventually let the system replay millions of student sessions to refine the Socratic policy.
Daniel has also published the architecture of Open Lesson itself, and it is closer to self-driving-car research than to a chatbot. He calls it the Student Trajectory model. There is a World Model that predicts where the learner's understanding is going to be in the next 30 to 60 seconds. There is a Socratic Policy, a reinforcement-learning agent trained on millions of simulated student sessions, that decides when to intervene, what kind of intervention to make, and what specific question or hint will produce the biggest leap in the student's trajectory. There is a Guarded Generator, a constrained LLM that produces only Socratic questions and hints, never answers. There is multimodal perception — vision and speech and behaviour — so the system can watch what you are doing and listen to you think aloud.
The model running underneath today is Grok. Daniel is training his own. Either way, this is not a wrapper. This is years of work, and most of it is in the open: the dataset is on Hugging Face, the benchmark is on GitHub, the writeups are on his blog. There is also a tokenized data-provider program he uses to fund dataset growth, which you can take or leave. The artifacts themselves are Apache-2.0 and do not require you to participate in any of it.
If you want to verify any of this, his YouTube channel is the most useful thing on the internet for it. He records himself doing self-study sessions live, on different topics, showing how he thinks. It is rare for a founder in this space to be that exposed about their own process.
How we met, and why we're complementary
We met three months ago on X, in a thread about learning.
I started beta-testing Open Lesson shortly after that, and giving Daniel feedback on the UX. The conversations got longer and we eventually connected over regular video calls. At some point, we both realised the products are doing complementary work.
Dantes maps the knowledge: the initial problem for any self-learner is finding the right resources — the books, courses, videos, papers across the whole map. Many learners have cut short their learning journey because they couldn't find any resource actually worth their time, or didn't know where to start. That is the pain Dantes solves.
Open Lesson teaches you to think through that knowledge. Once you have the resources, you still have to actually study them. That is the harder part. That is the part where most self-learners stall.
It also proves something I keep coming back to: social media is social, it still lets you meet people. I know some of my relatives find it odd, sometimes even dangerous, when I mention I've made friends online. Yet, I've got a few examples that prove them wrong.
Finally, sometimes, one person changes the trajectory of your project. Hopefully Daniel will be that person for Dantes.
The partnership today
The integration shipped last week. Concretely: when you land on a resource page on Dantes, you'll now see a small card inviting you to study the topic on Open Lesson. The copy is topic-specific, but I will work on a better implementation: as we saw above, the Socratic method is not always the best one, therefore I need to be more mindful on when we recommend its use. On the Analytic Geometry page, for example, the card reads:
"Test your understanding of Analytic Geometry. Explain it out loud. An AI tutor listens and asks questions that expose gaps you didn't know you had."
The CTA: "Study with openLesson."
 The Partnership Card. Source: Dantes.io.
The Partnership Card. Source: Dantes.io.
The other direction: when you launch a learning session on Open Lesson on a given topic, the resource tab inside the session features curated Dantes resources, among others, so you can go deeper without leaving the workflow.
That is the whole v1. It is a pure mutual link partnership, nothing else. I get no benefit from any subscription you may take — no referral fees, no revenue share, no equity. This is not the goal: I genuinely believe in the value offered by Daniel's product, hence why it is featured.
We are starting small on purpose, because we both believe there is much more to do, and we'd rather ship something honest than oversell something thin. The plan is to extend it with topic-specific roadmaps, and to think about deeper integration as both platforms grow up.
For full disclosure: Open Lesson is paid. Daniel needs to cover his token costs today and his model-training tomorrow. The pricing is $4.99 a month for five sessions, or $14.99 a month for unlimited. For that price, you get an actual AI tutor available 24/7, and the cost is less than the cheapest paperback you'd buy on the topic.
Learning starts at the wall
I want to close on the philosophy, because the partnership only makes sense if you buy it.
Most learning tools today route us around the wall. Answers on demand, autocomplete, the friendly tutor who explains too soon. We've all used Claude or ChatGPT that way: this is fine for a quick explanation, but it is not how you learn hard things.
I am not trying to replace teachers: I actually love studying and would gladly attend university again if I had more time. I don't think Daniel is either. There is real value in a person in front of you, someone who can read your face, point at things, and discuss what is around the topic and not just the topic itself. AI is a tool. It is not the only tool, and it should not be the only tool.
But there is a moment in learning where no teacher and no resource can help you. It is the moment when you are properly stuck. You have been through everything in memory, every methodology you have used before, and none of it is enough. That is the moment when you start going through new ways, new paths. A lot of those paths will go nowhere. That is fine. Going nowhere is itself learning. You walked the path, and now you can tell yourself: this approach is wrong for this kind of problem, but it might be right for that other one. You learned something even though you did not solve your original problem.
Self-learning is mostly that. It requires a lot of discipline, motivation, and patience. A lot of learners managed to kick things out but fail to find the relevant resources. Dantes solves that pain point. But then, you've got to study these resources. Put yourself in the right conditions. Be ready to challenge yourself, get frustrated, move forward, move backward, try a new path, and eventually get to the solution or a clear understanding. Open Lesson helps you with that.
Together, we provide you with a bookcase and the classroom. But it's for you to sit in front of your desk and pull the hard work.
Disclosure
This post announces a partnership in which Dantes and Open Lesson exchange traffic via mutual links on each platform. No referral fees, no revenue share, no equity changes hands in either direction. Open Lesson is a paid subscription product built by Daniel Colomer (uncertain.systems).
Further reading on the science
The references cited above, in order of appearance:
- Chi, M. T. H., & Wylie, R., 2014. The ICAP Framework: Linking Cognitive Engagement to Active Learning Outcomes. Educational Psychologist, 49(4), 219–243.
- Freeman, S., Eddy, S. L., McDonough, M., Smith, M. K., Okoroafor, N., Jordt, H., & Wenderoth, M. P., 2014. Active learning increases student performance in science, engineering, and mathematics. PNAS, 111(23), 8410–8415.
- VanLehn, K., 2011. The Relative Effectiveness of Human Tutoring, Intelligent Tutoring Systems, and Other Tutoring Systems. Educational Psychologist, 46(4), 197–221.
- Kapur, M., 2008. Productive Failure. Cognition and Instruction, 26(3), 379–424.
- Sinha, T., & Kapur, M., 2021. When Problem Solving Followed by Instruction Works: Evidence for Productive Failure. Review of Educational Research, 91(5), 761–798.
- Kapur, M., & Roll, I.. Productive Failure. Book chapter. The chapter sets out the design principles and fidelity conditions for a productive-failure implementation, with task-design features and a section on educational implications.
- Sinha, T., Kapur, M., West, R., Catasta, M., Hauswirth, M., & Trninic, D., 2021. Robust effects of the efficacy of explicit failure-driven scaffolding in problem-solving prior to instruction: A replication and extension. Learning and Instruction, 75, 101507.
- Chi, M. T. H., de Leeuw, N., Chiu, M.-H., & LaVancher, C., 1994. Eliciting Self-Explanations Improves Understanding. Cognitive Science, 18(3), 439–477.
- Bisra, K., Liu, Q., Nesbit, J. C., Salimi, F., & Winne, P. H., 2018. Inducing Self-Explanation: A Meta-Analysis. Educational Psychology Review, 30(3), 703–725.
- Bjork, E. L., & Bjork, R. A., 2011. Making Things Hard on Yourself, But in a Good Way: Creating Desirable Difficulties to Enhance Learning. In Psychology and the Real World.
- Jurenka, I. et al. (Google DeepMind LearnLM team), 2025. AI tutoring can safely and effectively support students: An exploratory RCT in UK classrooms.
- Kirschner, P. A., Sweller, J., & Clark, R. E., 2006. Why Minimal Guidance During Instruction Does Not Work. Educational Psychologist, 41(2), 75–86.
- Kalyuga, S., Ayres, P., Chandler, P., & Sweller, J., 2003. The Expertise Reversal Effect. Educational Psychologist, 38(1), 23–31.
Learn more about Daniel and the open stack
- The broader project: uncertain.systems
- The stack itself, layer by layer: uncertain.systems/stack
- GHC dataset on Hugging Face: huggingface.co/datasets/unsys/ghc
- GHC benchmark on GitHub: github.com/dncolomer/ghc-benchmark
- Daniel's writeups: uncertain.systems/blog
- Daniel's live self-study sessions on YouTube: channel
- Daniel on LinkedIn: profile
Go deeper
Test your understanding of learning
Explain it out loud. An AI tutor listens and asks questions that expose gaps you didn't know you had.